
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Direct2D
- doit코틀린프로그래밍
- 티스토리
- 리뷰
- VS ERROR
- 함수
- 이지스퍼블리싱
- Desktop
- CS
- c
- Tips프로그래밍강좌
- 문법
- Windows
- 지식나눔강좌
- Programming
- 알고리즘
- c#
- Kotlin
- 배열
- Javascript
- Tips강좌
- 포인터
- 백준
- Visual Studio
- Win32
- 프로그래밍
- c++
- 김성엽
- tipssoft
- 연산자
- Yesterday
- Today
- Total
F.R.I.D.A.Y.
함수 호출 구조 본문
포인터 파트에서 함수 호출 구조에 대해 잠깐 언급한 적이 있습니다. 이 포스트에서 그 내용을 다뤄볼 것입니다.
프로세스의 구조
프로세스[# 프로세스는 운영체제의 로더에 의해 프로그램이 메모리에 올라갈 때 CPU가 실행할 수 있도록 구조를 변경하여 메모리에 올라가 있는 바이트 코드를 의미합니다.]는 Windows 기준으로 하여 아래와 같은 구조[# 정확한 구조는 아니니, 이런 식으로 구성되어 프로세스에 올라간다고만 생각하기 바랍니다. 이 스택 프레임은 플랫폼, 언어, 개발자 구현 방식에 따라 달라질 수 있습니다.]를 가지고 있습니다.
| 코드 세그먼트 | 기계어(명령어) |
| 데이터 세그먼트 | 문자열 상수 목록 |
| 전역 변수 | |
| static 변수 | |
| 엑스트라 세그먼트 | 힙(Heap) |
| 스택(Stack) |
코드 세그먼트:
코드 세그먼트에서 관리하는 데이터는 CPU에서 실행되는 바이트 코드를 담고 있습니다.
데이터 세그먼트:
문자열 상수 목록: 프로그램을 작성하다가 쌍따옴표[# "]로 묶은 문자열을 담고 있는 공간입니다.
전역 변수: 함수 외 바깥에서 선언한 변수를 관리하는 공간입니다.
static 변수: 전역 변수의 특성[# 함수가 종료되어도 데이터가 유지됨. LifeCycle(생명 주기)이 프로그램과 같음]과 지역 변수의 특성[# 해당 변수가 선언된 블록과 그 안쪽 블록에서만 사용이 가능함]을 고루 갖춘 static으로 선언된 변수를 관리하는 공간입니다.
엑스트라 세그먼트:
힙(Heap): 동적 할당으로 메모리를 할당 받았을 때 사용하는 공간입니다.
스택(Stack): 코드상에 드러나 있는 메모리(변수 등)를 관리하는 공간입니다.
여기에서 우리는 스택 부분을 집중적으로 노려볼 것입니다.
스택
자료구조 스택과 이름이 같은 이 공간은 스택처럼 데이터를 위로 쌓고 위에서부터 꺼낸다고 하여 붙여진 이름입니다. 다음 코드를 보겠습니다.
#include <stdio.h>
void funcA(int v){
printf("%d\n", b);
}
void funcB(int* v){
printf("%d\n", *v);
}
int main(void){
int num;
num = 5;
funcA(num);
num = 13;
funcB(&num);
return 0;
}함수 funcA와 funcB, 그리고 엔트리 포인트인 main이 존재합니다. 이 함수를 실행할 때는 다음과 같이 스택이 구성됩니다.
실행에 따른 스택 변화
가장 먼저 main 함수에 대한 정보(변수 등)가 스택 메모리 공간에 쌓입니다. 그리고 작업을 진행하면서 funcA 함수와 funcB 함수가 호출되므로 각 함수에 대한 정보가 스택 메모리 공간에 쌓이고 사라집니다. 순서는 아래와 같습니다.
main 함수를 호출하는 함수에 대한 정보를 스택에 쌓습니다.

그리고 main 함수에서 사용하는 변수 등의 정보를 스택에 쌓습니다. 이 코드에서 사용할 변수는 하나 뿐이군요.

여러 연산 코드를 실행한 뒤 funcA 함수를 실행합니다. 따라서 현재 작동중인 main 함수에 대한 정보를 스택에 쌓아줍니다. 그리고 나서 funcA 함수의 인자로 int v가 존재하므로 그 위에 이 변수를 넣어줍니다.

# 이전 함수의 정보를 스택에 쌓는 이유?
이전 함수의 정보를 스택에 쌓는 이유는 호출된 자녀 함수[#동의어 callee 함수. 역 관계로는 caller 함수]가 실행 완료된 뒤 이전 함수에서 자녀 함수 이후에 실행될 코드를 정상적으로 실행하기 위함이 있습니다.
우리가 편지를 쓰다가 잠시 물을 가지러 다녀 왔다고 합시다. 물을 가지러 다녀온 뒤에 우리는 편지를 어디까지 썼는지 기억하고[# 혹은 읽어보고] 이어서 글을 작성해야합니다. 물을 가지고 왔는데 다음으로 쓸 글이 무엇인지 모른다면 편지의 내용이 이상할 것입니다. 시작에 "안녕하세요"를 이어 써야하는데 "안녕히 계세요"를 쓴다면 편지를 왜 써야하는지 의문일 것입니다.
funcA 함수 안에서는 printf 함수를 사용합니다. printf 함수를 이용하기 전에 funcA 함수에 대한 정보를 저장하고, 첫 문자열[# 이 문자열은 서식지정자를 0개 이상 포함하는 문자열입니다.]과 이어서 추가 정보로 사용하는 가변인자[#va_list 가변인자에 대한 설명은 이 페이지를 참고하세요.]의 정보를 넣습니다.
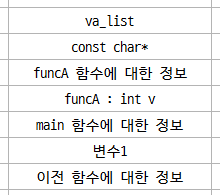
사용을 마치면 printf 함수에 대한 정보를 날려줍니다.

funcA 함수에서는 더이상 작업이 존재하지 않으므로 funcA 함수에 대한 정보를 날리고 main 함수에 대한 정보로 스택을 롤백[# 이전으로 되돌림]합니다.

연산하는 코드는 스택에 영향을 주지 않으므로 넘어가고, 이어서 funcB 함수에 대한 과정을 위와 같이 반복합니다. 그리고 main 함수의 마지막 작업이 완료되면 main 함수가 실행되기 이전으로 스택 정보를 롤백합니다.
번외. 재귀 함수가 좋지 않은 이유
종종 재귀함수를 지양하라는 말을 듣습니다. 구현을 쉽게 할 수 있는 장점이 있지만 단점이 존재하기 때문인데요, 그 단점이 이 스택 프레임에 의해 발생하는 것입니다.
void fibo(int a){
if(a <= 1) return 1;
else fibo(a - 1) + fibo(a - 2);
}피보나치 수 구하는 재귀함수입니다. 이 코드의 경우 스택 프레임에 fibo 함수의 정보를 반복적으로 담아야합니다. 따라서 1MB[# Windows OS 기준]의 공간만 가지고 있는 스택의 범위를 쉽게 초과할 수 있고 이렇게 범위를 초과하면 스택 오버플로우로 인해 프로그램이 종료될 수 있습니다.
문단의 제목으로 재귀 함수가 좋지 않은 이유로 작성하였지만, 재귀 함수가 꼭 나쁜 것은 아닙니다. 서두에 말 했듯이 알고리즘의 구현이 쉽고, 반복문[# 재귀함수를 이용할 수 있다면 복잡하더라도 반복문으로 해결 가능한 경우가 많다.]을 이용한 코드보다 직관적일 수 있다는 장점이 있습니다. 본인의 프로그램에 더 나은 선택을 하는 것은 개발자 본인의 몫입니다.
# index
'DEV > C C++' 카테고리의 다른 글
| 포인터(pointer) part2. 다차원 포인터 (0) | 2020.01.17 |
|---|---|
| CallByValue vs CallByReference (0) | 2020.01.09 |
| 포인터 part1. default (0) | 2020.01.07 |
| 배열 변수의 이름이 0번 인덱스의 시작 주소인 이유 (0) | 2020.01.06 |
| typedef (0) | 2020.01.04 |



